Что такое большие данные?
In short, the term Big Data applies to information that can’t be processed or analysed using traditional processes or tools.

MapReduce
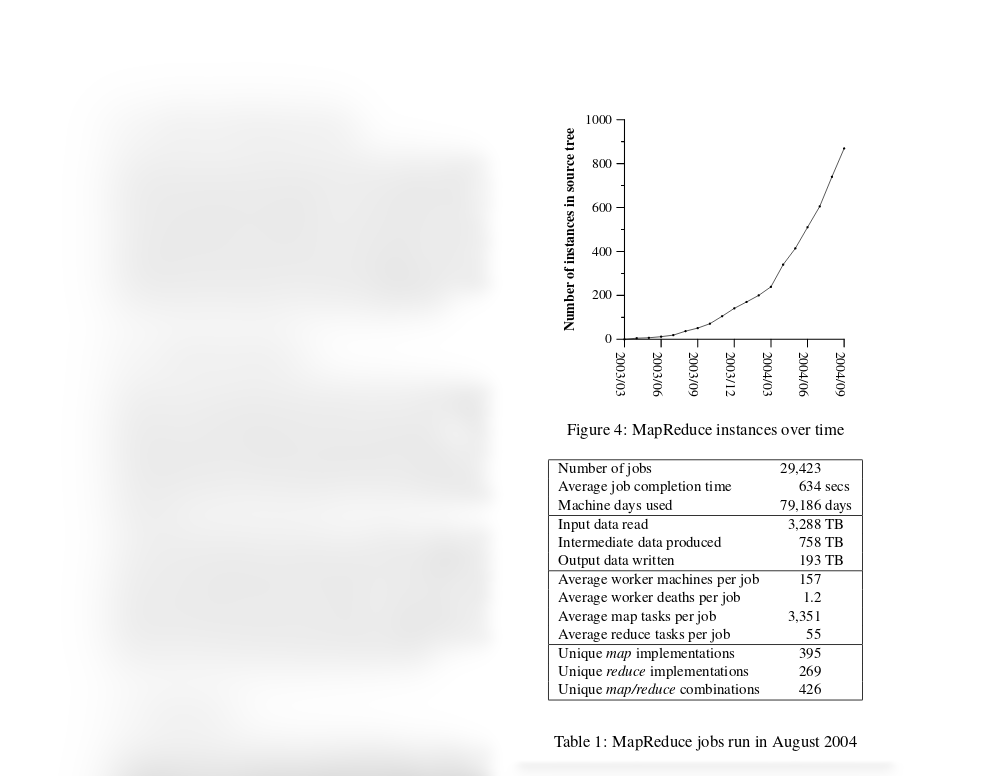
Алгоритм MapReduce

Алгоритм MapReduce

Алгоритм MapReduce

Алгоритм MapReduce

Алгоритм MapReduce
- Высокий параллелизм по данным.
- Автоматическое обеспечение отказоустойчивости.
- Достаточная универсальность для реализации часто используемых алгоритмов.
Hadoop vs. HPC
| Big Data | HPC | ||
|---|---|---|---|
| Файловая система | Размер блока | 64МБ | 4Кб |
| POSIX | нет | да | |
| Произвольный доступ | нет | да | |
| Репликация | да | да | |
| Планировщик | Отказоустойчивость | отдельные процессы | приложения целиком |
| Программный интерфейс | YARN API + Hadoop | ??? + MPI | |
| Запуск приложений близко к данным | да | нет | |
 |  |
Экосистема Hadoop

Apache Spark
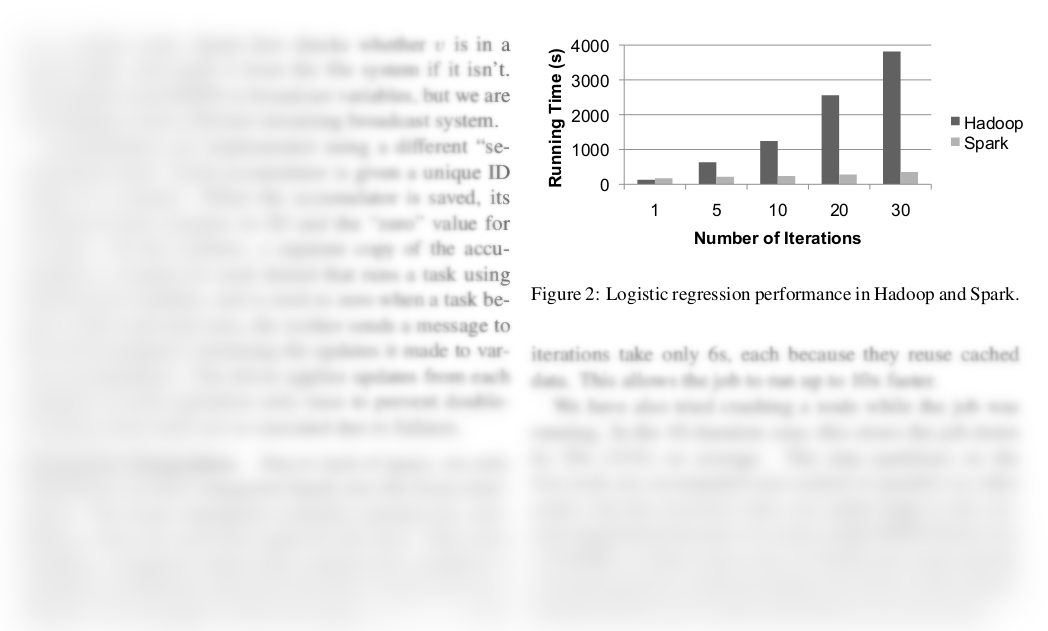
Spark: частота повторения слов
val file = sc.textFile("..."); file.flatMap(line => line.split("\W+")) .filter(word => !word.isEmpty()) .map(word => (word, 1)) .reduceByKey((a, b) => a + b) .map(pair => pair.swap) .sortByKey(false) .collect() |  |
Spark: потоковая обработка
val conf = new SparkConf().setAppName("NetWordCount") val ssc = new StreamingContext(conf, Seconds(1)) ssc.socketTextStream("127.0.0.1", 7777, StorageLevel.MEMORY_AND_DISK_SER) .flatMap(_.split(" ")) .map(x => (x, 1)) .reduceByKey(_ + _) .foreachRDD(rdd => { // RDD functions }) ssc.start() ssc.awaitTermination() |  |